Overview of Linked Lists
Introduction
Fundamental data structures like linked lists provide a dynamic and adaptable approach to storing and arranging data. Linked lists allow for the dynamic development and reduction of data elements in contrast to arrays with a fixed size. The ideas of linked lists will be covered in detail in this article, along with the two main types (singly linked lists and doubly linked lists), various operations related to them, implementation details, use cases, and the intriguing idea of circular linked lists.
Understanding Linked Lists
A linked list is a common linear data structure consisting of a list of nodes. Each node in this structure has information and a pointer or link that points to the node after it in the sequence. Linked lists are the best choice when data needs to be effectively inserted, removed, or traversed frequently because of their inherent flexibility. Unlike arrays, linked lists can adjust to changing data needs by dynamically growing or contracting to fit the components.
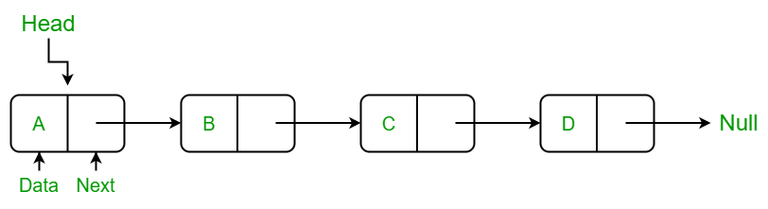
Singly Linked Lists and Doubly Linked Lists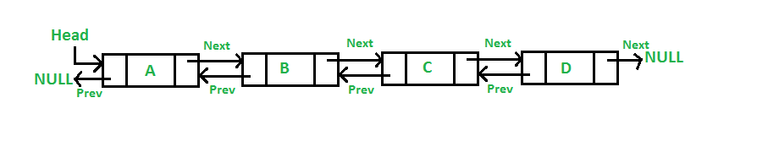
Linked lists come in two primary forms: singly linked lists and doubly linked lists. Let's take a closer look at these two variations.
1. Singly Linked Lists:
- In a singly linked list, each node contains data and a reference to the next node in the sequence.
- These lists are unidirectional, meaning you can only traverse them in one direction – from the head (the first node) to the tail (the last node).
- Singly linked lists are relatively simpler to implement and are memory-efficient since they only store a single reference.
2. Doubly Linked Lists:
- Doubly linked lists, on the other hand, offer bidirectional traversal. Each node contains two references – one pointing to the next node and another to the previous node.
- This bidirectional traversal feature enables more versatile operations like reverse traversal and deletion of a node with a direct reference to it.
- However, this added flexibility comes at the cost of increased memory usage, as each node in a doubly linked list stores two references.
Operations on Linked Lists
Linked lists support several key operations:
- Insertion: Adding a new node to the list, whether it's at the beginning, end, or any position in between.
- Deletion: Removing a node from the list, either by specifying the node to be deleted or its position.
- Searching: Locating a specific node within the list.
- Traversing: Moving through the list from one node to another to access or modify data.
- Manipulating: Making changes to the data or the structure of the linked list.
Implementation and Use Cases
Implementing a linked list involves creating the necessary data structures and algorithms for these operations. While they may not be as efficient for certain tasks as arrays, linked lists excel in scenarios where data manipulation is frequent and requires adaptability.
Common use cases for linked lists include:
- Manipulating data
- Making use of stacks and queues.
- Creating hash maps and tables.
- Mathematical representation of polynomials.
- Managing huge datasets with inconsistent memory allocation.
Circular Linked Lists
In addition to singly and doubly linked lists, there's the concept of circular linked lists. These lists form a closed loop, where the last node connects back to the first node, creating a circular structure. This unique property has applications in tasks where cyclical operations or continuous data access is needed.
Conclusion
Linked lists help manage data in a dynamic and adaptable manner. It is crucial for any programmer to understand the two types of linked lists, the operations they support, their implementations, and their potential use cases. Whether it's singly or doubly linked lists or even intriguing circular linked lists, each variant offers a unique set of features to cater to different data management needs. Linked lists offer a versatile and effective way to store and arrange data components dynamically.
Posted using Honouree